
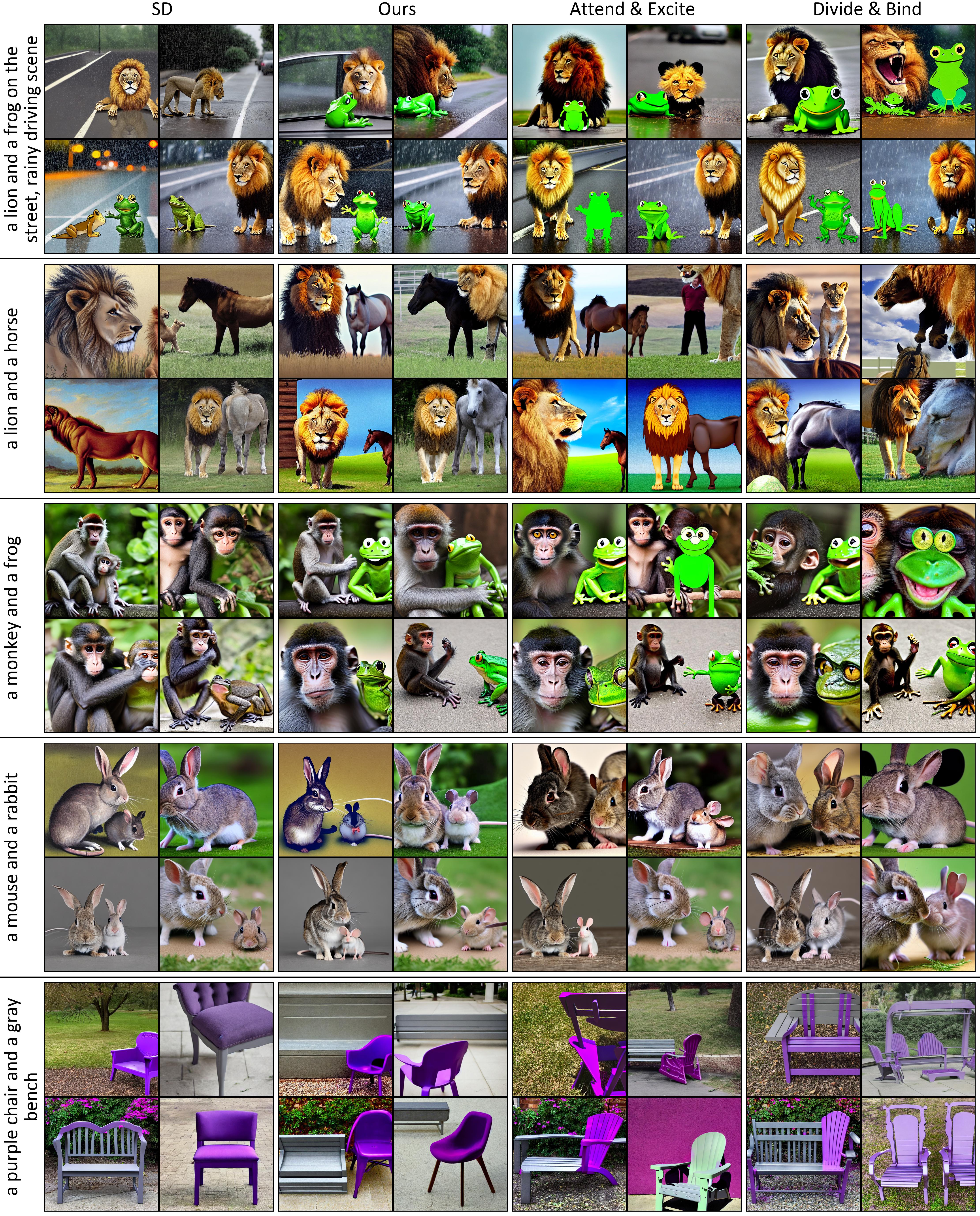
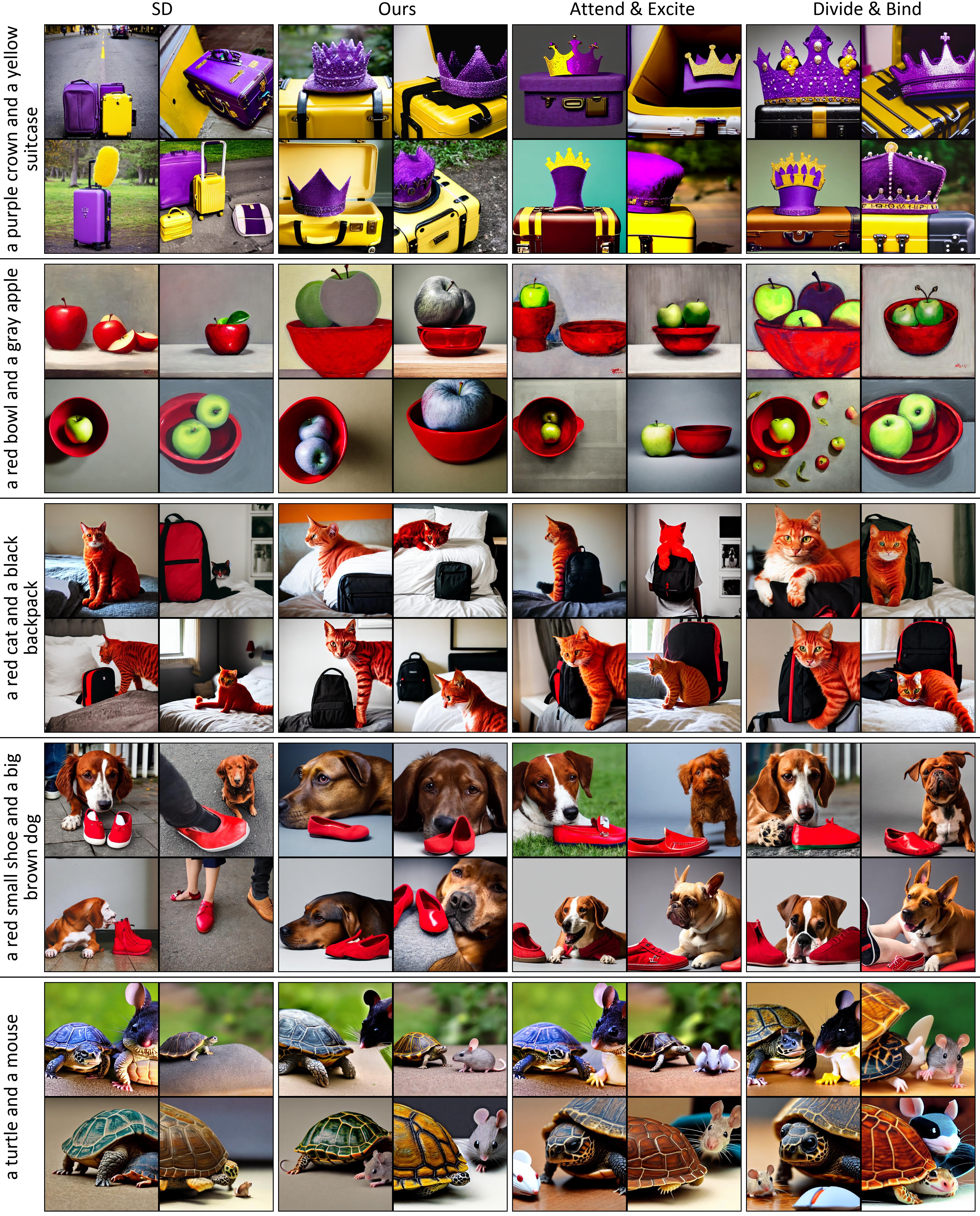
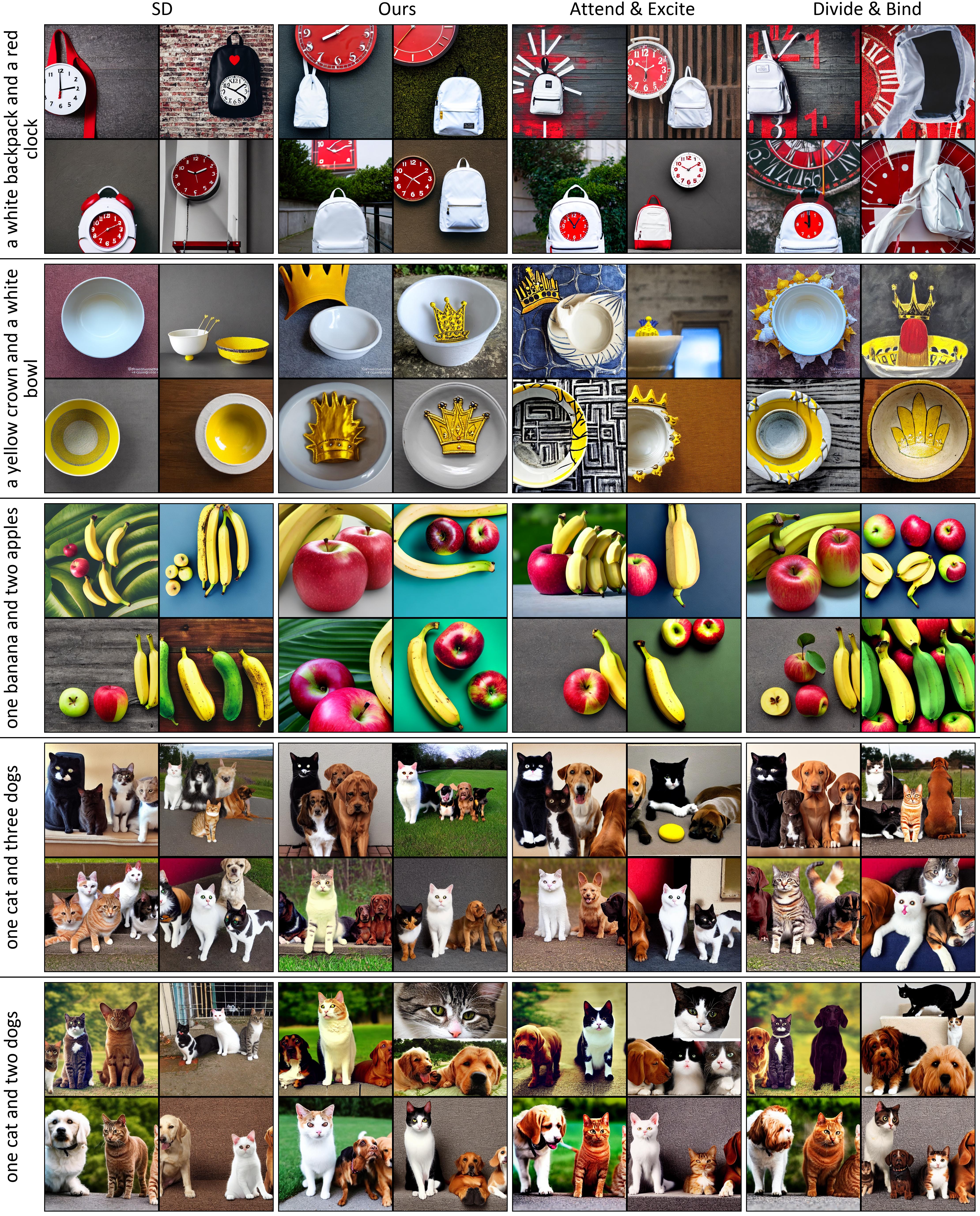
Images produced by text-to-image diffusion models might not always faithfully represent the semantic intent of the provided text prompt where the model might overlook or entirely fail to produce certain objects. While recent studies propose various solutions, they often require customly tailored functions for each of these problems, leading to sub-optimal results, especially for complex prompts. Our work introduces a novel perspective by tackling this challenge in a contrastive context. Our approach intuitively promotes the segregation of objects in attention maps, while also maintaining that pairs of related attributes are kept close to each other. We conducted extensive experiments across a wide variety of scenarios, each involving unique combinations of objects, attributes, and scenes. These experiments effectively showcase the versatility, efficiency, and flexibility of our method in working with both latent and pixel-based diffusion models, including Stable Diffusion and Imagen. Moreover, we publicly share our source code to facilitate further research.

The output might neglect certain subjects, as in the 'a bear and an elephant' prompt, where the bear is ignored as depicted in Figure (a). Additionally, the model might mix up attributes, such as mixing the colors in the 'a purple crown and a yellow suitcase' prompt as seen in Figure (b). Another behavior that is often attributed to the imprecise language comprehension of the CLIP text encoder is the failure to produce the correct quantity of subjects as in Figure (c) where the model either produces an excessive number of cats (SD) or failed to include a cat (Imagen) for 'one dog and two cats' prompt.















@InProceedings{Meral_2024_CVPR,
author = {Meral, Tuna Han Salih and Simsar, Enis and Tombari, Federico and Yanardag, Pinar},
title = {CONFORM: Contrast is All You Need for High-Fidelity Text-to-Image Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {9005-9014}
}